Application partitioning is a vital process, as it provides one with the opportunity to clearly define an even distribution of an application’s presentation, process, and key data components – without which, you may find yourself feeling quite lost. The components may be distributed over several different physical machines, or across a vast array of memory address spaces.
partitioning is a vital process, as it provides one with the opportunity to clearly define an even distribution of an application’s presentation, process, and key data components – without which, you may find yourself feeling quite lost. The components may be distributed over several different physical machines, or across a vast array of memory address spaces.
Application partitioning serves to maximize the inherent benefits of a multi tiered computer model, in that it distributes application processing across all spectrums of the system’s resources. For those who wish to achieve quality N-Tier distributed computing throughout their Business, application partitioning is a necessary step. How it is done can be critical for the outcome of the N-Tier application.
When it comes to the successful execution of an application partition, the only limitation of the number of tiers is the number of computers available. As the load of processing is theoretically meant to be distributed across a vast array of different processors, the ultimate in N-Tier client server scalability can be attained via the process of application partitioning.
In the past, client server architectures were riddled with numerous problems and limitations. Some of these included a low level of reliability, an excessive amount of clients that resulted in overloading, reduced bandwidth on a network, a reduced level of performance, high maintenance needs, and a low level of flexibility. Application partitioning is a successful way of overcoming all these limitations.
Application partitioning provides users with two essential benefits. The first is that it reduces the amount of turnaround time that is necessary for the data result. At the same time, it decreases the level of network traffic that necessitates the data transfer to the client.
The partitioning of applications is a major void filler when it comes to large scale client server systems. Application partitioning allows for a flexible distribution of application logic, the end result being an optimization of performance.
Of course, a successful application partitioning project is largely contingent on quality tools that will be able to leverage such emerging technologies as object oriented systems as well as peer to peer communications. As a result, better performance, reliability, transparency, and flexibility are all provided for large scale enterprise wide computing systems – in short, a must for any successful Business operating in this day and age.
Application Development
The partitioning of application provides a client server application development team with sufficient tools needed to support the architecture of an N-Tier application, as well as the capability of constructing an application that is truly distributed.
With the use of application partitioning instruments, the application can be designed on a single client PC machine. Afterwards, parts of it can then be relocated to any server that the network is able to access.
The application should be viewable by developers as a single logical program. The developers should not have to concern themselves with such issues as what components are going to be deployed on clients and what components will be deployed on servers, or whether the machines in question shall be Macintoshes or PC computers.
Once the application has been built and tested, it will be possible to partition it. That should theoretically be as simple a task as merely dragging an application object over to a server icon. Application partitioning tools are then generated and compiled on to native 3GL code in the background on the target servers, which in turn perform the necessary processing.
A client program containing one or more service programs should be the end result.
Such programs are meant to be run on specific forms of hardware, and to also interface with designated software, such as operating systems, GUI, middleware, database management systems, or communications mechanisms.
N-Tier Application Partitioning Benefits
Application partitioning brings with it numerous benefits. Some of these benefits appeal to the more Business oriented consumer, while other benefits fall on the technical side of things.
In today’s Business environment, it is of vital importance to take in to consideration performance issues. Those who use client server application development tools of the first generation often come to the conclusion that such simple applications, which typically consist of interpreted 4GL code that runs either on PCs or on work stations, might very well indeed provide adequate response times to a limited array of users; the problem is when the quantity of users increases, or when more complex applications are needed. In those instances, the level of performance (i.e. perceived user response times) is not likely to be very adequate.
The deployment of application components that are involved in major Business processes on a strong UNIX server that is accessible to all client PCs can do you a major favor by freeing up scarce resources on the PC clients so that presentation components may be freely accessed.
At the same time, by placing those application components that perform the majority of the interactions with the RDBMS on the same machine that the RDBMS is on, one can seriously reduce the amount of network traffic as well as the network resources’ contention.
Another benefit of application partitioning is an increase in application performance. It enables data processing logic to be closer to the data, while Business processing logic can be placed on to a faster application server.
In short, the primary benefits of application partitioning are an increase in the scalability of applications; the support of numerous and diverse configurations for both hardware and software; an increase in security that allows one to isolate sensitive processes that may also be Business critical; a higher degree of maintenance capabilities that enable one to isolate components of the application that tend to change often, and only one or a few copies of the utilized components; the reuse of components and objects – this enables services to be shared among and within various applications; an increase in support of the organization’s overall structure – Business data and Business processing logic are readily available to be deployed and in close proximity to end users and / or owners; and a separation of the rules of Business from both data and presentation.
Moreover, services can be readily partitioned in order to allow for sharing – and that extends not merely to clients working within a particular application, but among clients working in several different (separate) applications.
Objects and Components
Taking such a modular approach to application design, coupled with defining and using well defined component interfaces, lets vital bits of Business processing logic (i.e. rules of the Business) to be defined in Business Objects and subsequently reused among numerous different application subsequently. This type of reuse enables consistency to function across the Business while also allowing for maintenance to be easily performed, as the components that are reusable can readily be employed in several places, but their definition and maintenance occurs in just one place. Moreover, any single component of the application in question can be simply updated without interfering with any other components.
Another option is to alter the platform upon which several specific components are operating. For example, one can upgrade a server machine to a newer model that contains more processing power – and do that without having to alter the components that are running on other servers or clients.
N-Tier Applications
N-Tier applications are useful, in that they are able to readily implement Distributed Application Design and architecture concepts. These types of applications also provide strategic benefits to solutions at the enterprise level. It is true that two tier, client server applications may seem deceptively simple from the outset – they are easy to implement and easy to use for Rapid Prototyping. At the same time, these applications can be quite a pain to maintain and secure over time.
N-Tier applications typically come loaded with the following components:
- Security. N-Tier applications come with logging mechanisms, monitoring devices, as well as Appropriate Authentication, ensuring that the device and system is always secure.
.
- Availability + Scalability. N-Tier applications tend to be more reliable. They come loaded with fail over mechanisms like fail over clusters to ensure redundancy.
.
- Manageability. N-Tier applications are designed with the following capabilities in mind: deployment, monitoring, and troubleshooting. N-Tier devices ensure that one has the sufficient tools at one’s disposal in order to handle any errors that may occur, log those errors, and provide guidance towards correcting those errors.
.
- Maintenance. Maintenance in N-Tier applications is easy, as the applications adopt coding and deployment standards, as well as data abstraction, modular application design, and frameworks that enable reliable maintenance strategies.
.
- Data Abstraction. N-Tier applications make it so that one can easily adjust the functionality without altering other applications.
As useful as they are, there are also situations when an N-Tier application might not be the most ideal solution for one’s Business needs. Most of all, one should keep in mind that building an N-Tier application involves a lot of time, experience, skill, commitment, and maturity – not to mention the high cost. If one is insufficiently prepared in any of these areas, then building an N-Tier application might not be appropriate for you at this moment. Above all, building a successful N-Tier application necessitates a favorable cost benefit ratio from the outset.
First off, you should fully understand what an N-Tier application is, what it does, and how it functions. To put it the simplest terms possible, N-Tier applications help one distribute a system’s overall functionality in to a multitude of layers or “Tiers”.
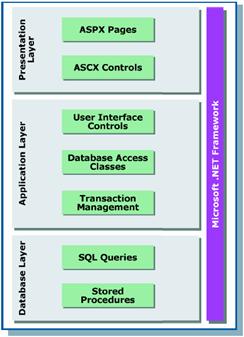
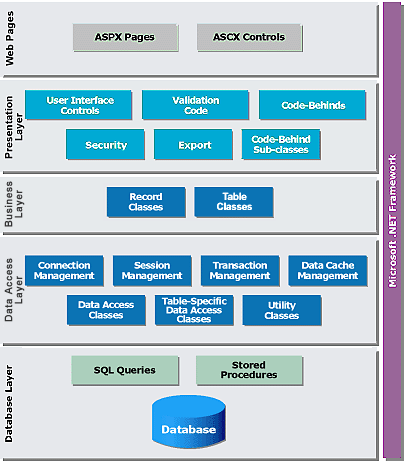
In a usual implementation, for example, you will most likely have at least some of the following layers, if not all: Presentation, Business Rules, Data Access, and Database. In some instances, it could be possible to split one or more of these different layers in to many different sub layers. It is possible to develop each of these layers separately from the others, as long as it can communicate with the other layers and adhere to the standards that have been set out in the specifications.






 7/29/2012 10:24:00 am
7/29/2012 10:24:00 am
 Sarkari Job
Sarkari Job